Can Language Beat Numerical Regression?
Language-Based Multimodal Trajectory Prediction
— and —
Social Reasoning-Aware Trajectory Prediction
via Multimodal Language Model
Inhwan Bae, Junoh Lee and Hae-Gon Jeon*
Computer Vision and Pattern Recognition 2024 and
IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract
Language models have demonstrated impressive ability in context understanding and generative performance. Inspired by the recent success of language foundation models, in this paper, we propose LMTraj (Language-based Multimodal Trajectory predictor), which recasts the trajectory prediction task into a sort of question-answering problem. Departing from traditional numerical regression models, which treat the trajectory coordinate sequence as continuous signals, we consider them as discrete signals like text prompts. Specially, we first transform an input space for the trajectory coordinate into the natural language space. Here, the entire time-series trajectories of pedestrians are converted into a text prompt, and scene images are described as text information through image captioning. The transformed numerical and image data are then wrapped into the question-answering template for use in a language model. Next, to guide the language model in understanding and reasoning high-level knowledge, such as scene context and social relationships between pedestrians, we introduce an auxiliary multi-task question and answering. We then train a numerical tokenizer with the prompt data. We encourage the tokenizer to separate the integer and decimal parts well, and leverage it to capture correlations between the consecutive numbers in the language model. Lastly, we train the language model using the numerical tokenizer and all of the question-answer prompts. Here, we propose a beam-search-based most-likely prediction and a temperature-based multimodal prediction to implement both deterministic and stochastic inferences. Applying our LMTraj, we show that the language-based model can be a powerful pedestrian trajectory predictor, and outperforms existing numerical-based predictor methods. Extensive experiments show that our LMTraj can successfully understand social relationships and accurately extrapolate the multimodal futures on the public pedestrian trajectory prediction benchmark.
Summary: Language model-based, Multimodal input, Multimodal output, Multi-task training approach for Zero-shot and Supervised human trajectory prediction.
Presentation Video
Motivation
Prediction From Numerical Trajectory Data
Beginning with physics-based mathematical formulation methods, The mainstream models take pedestrians' positions in world coordinates as input and infer their possible future paths by regressing a set of coordinate sequences. These numerical models threaten the trajectory coordinate sequence as continuous signals and directly use the numerical values.
Numerical-Based Interaction Modeling
The most crucial component in trajectory prediction tasks is modeling interactions between agents. All trajectory prediction models capture social relations between pedestrians based on their features or actual distance and motion similarity. However, these approaches fundamentally cannot learn social norms or human thought processes beyond numerical data.
💬 LMTrajectory Framework 🗨️
Language-Based Trajectory Prediction
In this paper, we investigate the feasibility of using natural language processing (NLP) to infer the future trajectories of pedestrians. We attempt to bridge the gap between traditional trajectory predictors and the capability of contemporary language models, offering a holistic solution for forecasting in crowded scenarios. Here, we introduce the Language-based Multimodal Trajectory predictor (LMTraj), which reevaluates language models from their foundational levels for numerical forecasting.
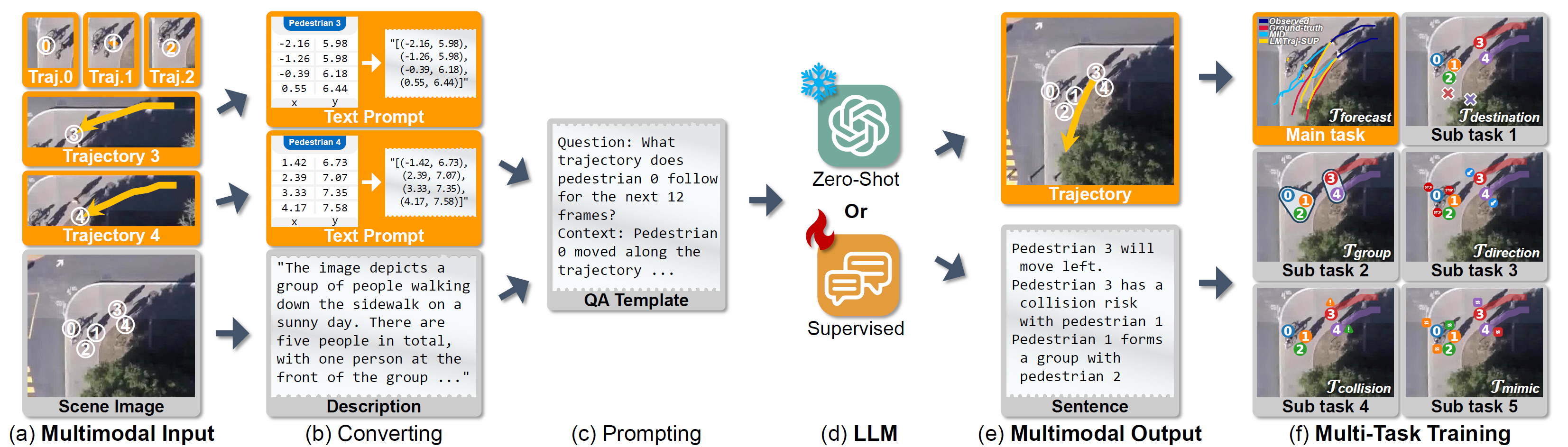
Data Space Conversion to Prompt
To make predictions using a language model, we first need to convert the raw data into text prompts. The most common data used in trajectory prediction are numerical coordinate sequences and top-down view images of a scene. In this paper, we start by transforming the pedestrian trajectory and environmental data. First, the entire float-type coordinate value is converted to a text string with decimal representation. Second, the scene image is converted to a textual description through a pretrained image captioning model. Next, we aggregate the converted data into linguistic sentences using a QA template for the input and output of the language model.
Optimizing the Tokenizer for Numeric Data
After the conversion process, we revisit each component of the conventional NLP pipelines and introduce a domain adaptation for LMTraj-SUP. The first component we revisit is the tokenizer. A tokenizer is essential for breaking text down into smaller units called tokens. Existing studies directly employ pretrained tokenizers, but these are optimized for text data and disrupt the training of consecutiveness and associations between adjacent numbers. To address this issue, we train a new tokenizer specifically for numerical data using our QA prompts. Our numerical tokenizer effectively breaks down words, integers, and decimal parts.

Multi-task Training for Social Relation Reasoning
Second, it is widely known that language models can achieve high-level knowledge understanding through multi-task learning. To enhance reasoning capacity with social relations, we introduce auxiliary tasks that leverage the model's understanding and reasoning abilities for both scene context and social dynamics. Compared to the numerical modeling approach, our method can utilize additional knowledge of human relationships embedded in a pretrained language model. We implement these synthetic tasks using pseudo labels generated only with observation trajectories for a fair comparison with previous works.

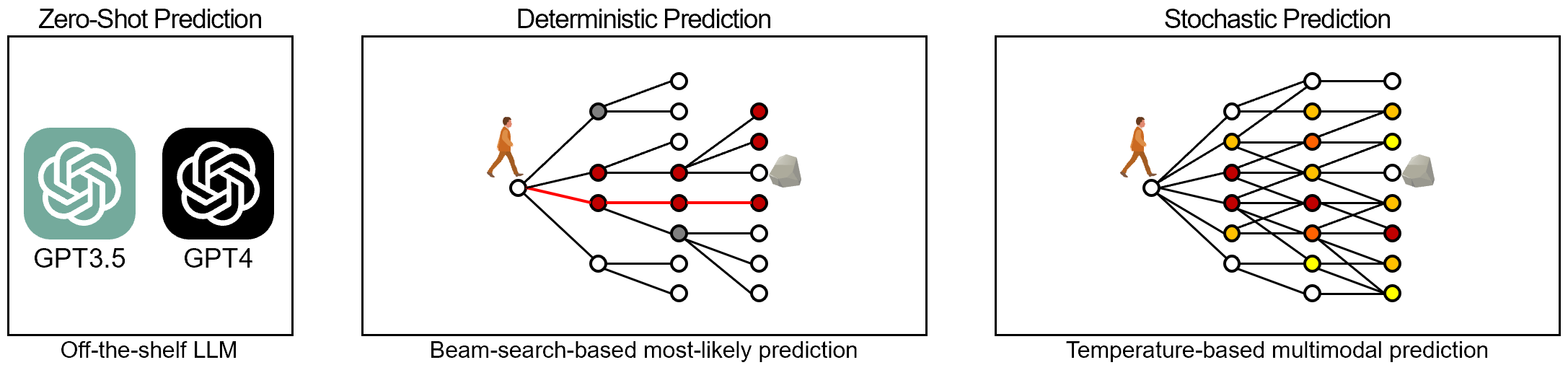
Generating Most-Likely and Multimodal Outputs
Lastly, in trajectory prediction, generating all possible multiple paths or the single most likely path is crucial. We handle this stochasticity by introducing a text generation technique. Using beam search, the language model can predict the path with the highest probability. Next, the model can generate diverse outputs by modulating the token probability using a temperature parameter. By employing these techniques, the language-based model can perform on par with and potentially replace existing predictor methods.
Forecast With the Language Model
Lastly, we incorporate our proposed methods into the trajectory forecasting model. To do this, we adopt two widely-used approaches in computer vision and natural language tasks: (1) conducting zero-shot evaluation through prompt engineering of a pretrained language foundation model, LMTraj-ZERO, and (2) end-to-end supervision, LMTraj-SUP. First, we perform prompt-tuning on pretrained large language models, GPT-3.5 and GPT-4, which were not originally trained for trajectory forecasting. In this approach, the language model is frozen and neither trained nor fine-tuned. Second, we evaluate the maximum capacity and performance of the language model through end-to-end training. In trajectory prediction, it has been proven that an encoder-decoder architecture is superior to procedural generation from recurrent models. Therefore, we use the T5 model, a sentence-to-sentence encoder-decoder language model, as our backbone.
Language Model Excels In...
(a) Trajectory Pattern Completion
Our language-based model has many advantages over traditional numerical methods. Firstly, it can predict personalized walking patterns by imitating a person's past behavior, where the traditional numerical-based methods completely fails and even struggling in predicting the walking direction. This is because these patterns act as perturbed noise for numerical models. Our LMTrajectory attempts pattern completion by identifying such patterns from past trajectories, replicating them, and applying them to future pathways. This demonstrates the potential effectiveness of personalized trajectory predictors.
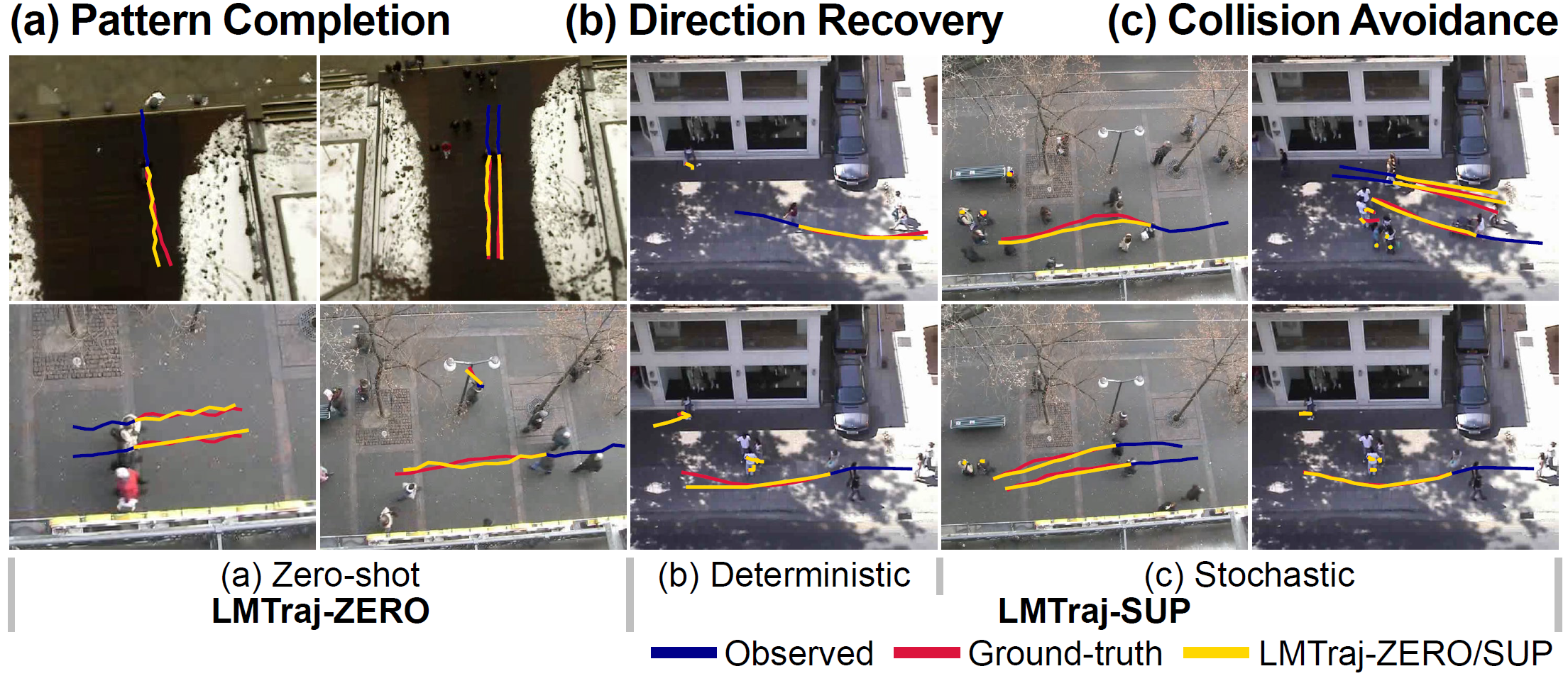
(b,c) Collision Avoidance
Secondly, our language model can effectively return to its original direction after achieving an intermediate goal. Through our social reasoning, the model clearly understands the surrounding context and accurately predicts the most likely path using beam search. This enables significant performance improvements in deterministic trajectory prediction. Similarly, it demonstrates highly accurate and realistic collision avoidance capabilities in the stochastic prediction case. our LMTraj predicts highly accurate paths that maintain momentum while avoiding group-to-group collision. This is realized when incorporating social reasoning, which allows to estimate groups and to predict potential collisions between all pedestrians within a scene.

(d) Social Reasoning
In social reasoning, our model surpasses conventional black-box approaches by leveraging directly relevant knowledge for more precise predictions. Unlike black-box models that rely solely on numerical data and lack interpretability, our model utilizes contextual and relational information embedded in pretrained language models. This enables a better understanding and prediction of complex social interactions and dynamics between agents, resulting in more accurate and reliable trajectory predictions. Additionally, the use of natural language processing techniques allows our model to incorporate a broader range of human-like reasoning and knowledge, further enhancing its predictive capabilities.
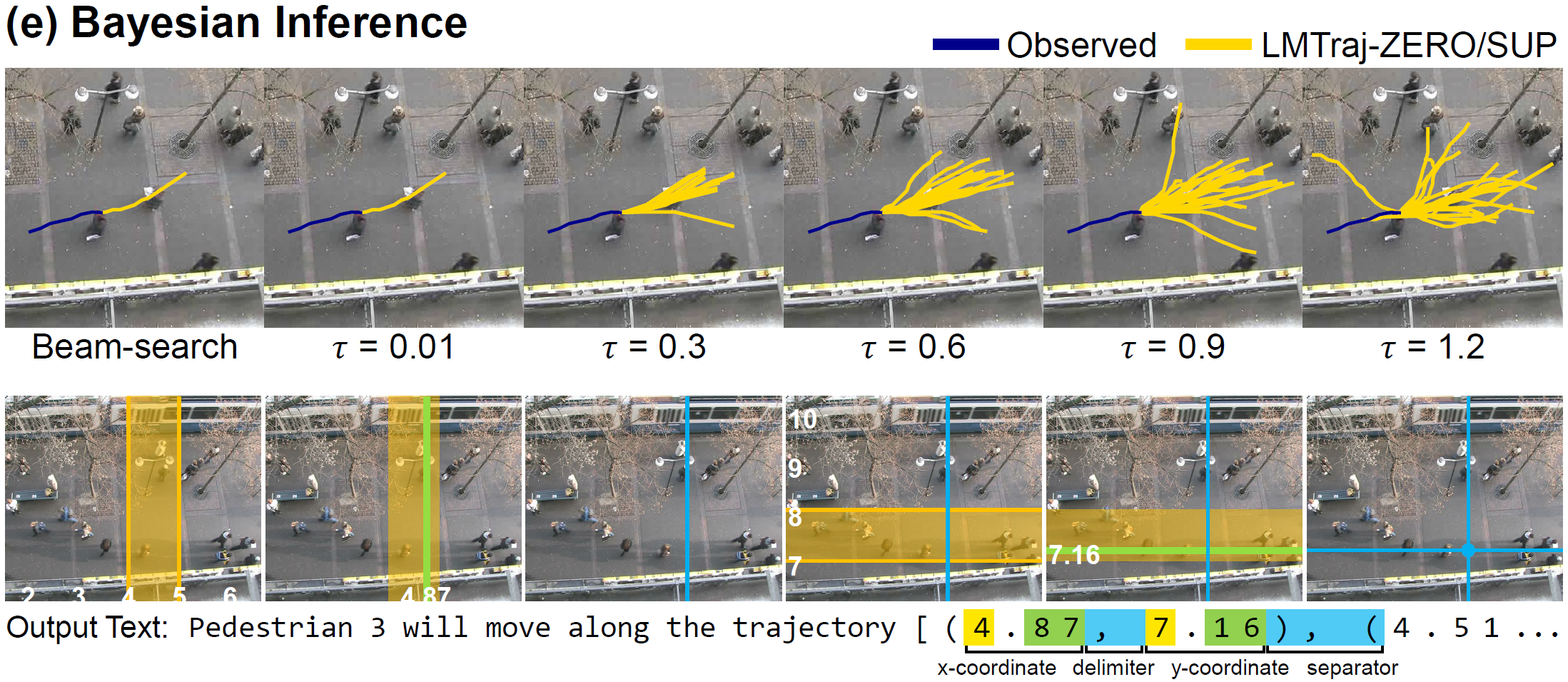
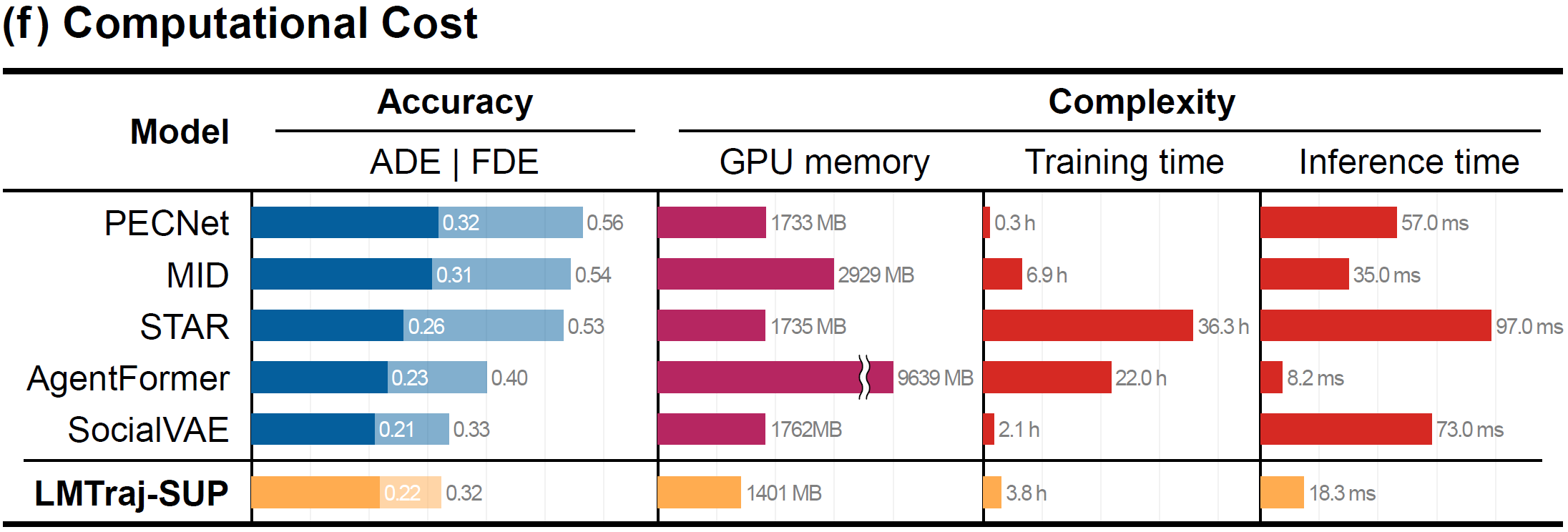
(e) Bayesian Inference and (f) Computational Cost
Following Bayesian inference principles, the language model can determine both the most likely deterministic paths and multimodal stochastic routes while ensuring the surrounding interactions. Lastly, our model provides computational cost benefits by leveraging an optimized framework, compared to increasingly complex numerical models.
Qualitative Results

BibTeX
@inproceedings{bae2024lmtrajectory,
title={Can Language Beat Numerical Regression? Language-Based Multimodal Trajectory Prediction},
author={Bae, Inhwan and Lee, Junoh and Jeon, Hae-Gon},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
@article{bae2025vlmtrajectory,
title={Social Reasoning-Aware Trajectory Prediction via Multimodal Language Model},
author={Bae, Inhwan and Lee, Junoh and Jeon, Hae-Gon},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2025}
}